Overview
I joined Collectors in August 2022 as a Database Engineering Manager and the first major task assigned to me was to migrate databases from an aging on-premise architecture to a more robust cloud infrastructure within a 1-2 year timeframe. Collectors is a company formed in 1986 with dozens of applications, supporting both internal operations, mobile apps, and external websites. As these applications have undergone modernization, the databases remained in a data center that incurred significant rent and manpower to manage the hardware infrastructure and backups, as well as the redundant hardware and vast storage arrays needed in order to support ever-increasing storage & compute capacity, and uptime/recovery requirements. Collectors has formed a trusted, robust relationship with Amazon Web Services (AWS), and moving our on-premise databases to the AWS Relational Database Services (RDS) platform was a natural consideration since AWS has been instrumental in enabling Collectors to take full advantage of the benefits of being in the cloud.
Two of Collectors’ primary SQL Server instances were identified as candidates for the migration (referred to as Server1 and Server2), holding some 80-90 related and not-so-related databases: some are huge, and some are tiny; some have massive OLTP concurrency, while some are used for reporting and are OLAP-focused. What this means is that the workload is extremely diverse, and the database servers are very large and quite volatile with unpredictable workloads. In this article, I will provide the narrative of our database migration at Collectors, and consider that these particular strategies can be generalized and used with differing technology platforms; the same concepts for the migration will apply.
Problem Statement
As Collectors continues to grow its business both vertically and horizontally, our on-premise database systems were starting to show lots of strain and pressure. Such as:
- No ability to scale up or down, or upgrade database hardware.
- Complicated backup and recovery procedures.
- Lack of adequate HA/DR (and actual RTO/RPO for on-prem SQL Servers was unknown).
- Server and database administration activities like storage expansions, backups, and security patching of database and operating systems, takes away valuable engineering time.
Migration Process Outline at Collectors
Take inventory of the data being migrated
The first step of a “cloud migration” is to define the scope of the migration and find the dependencies. We needed to identify the applications and stakeholders who should be engaged in the process.
One of the first gaps identified by the DBE team was that there was no comprehensive “List of Applications” acting on these two SQL Servers. We took time to audit all activity on the database instances, then prepared a list of all in-scope applications accessing those databases. Finally, we engaged the various development teams in order to find the owners of each application. Collectors, being a company that has been around for more than 30 years, has many applications (including legacy applications) totaling over 300 unique applications! I have been part of many migrations and database upgrades in the past, but this migration was more complex due to the large size of data being migrated in conjunction with a minimal maintenance window to perform the cutover, as well as the significant inter-dependencies between databases.


To migrate these servers separately wouldn’t be like unzipping a zipper, it would be like peeling apart two long strips of velcro – and investigating and accommodating every hook and latch (database call)! In addition, this project was initiated and driven by the Database Engineering Team as opposed to being a top-down organization-wide project involving all app teams. Tech Org Leadership fully supported the cross-team cycles required to get this inventory completed; without this support, this project could not have launched, let alone have any realistic chance of succeeding.
Collaborate with your stakeholders
Data migration is not only a deeply technical process, but also a business and organizational process that involves multiple stakeholders, such as engineering owners, users, managers, and vendors. Because of this, communication and collaboration with your stakeholders throughout the entire data migration project – from planning to execution to evaluation – is imperative! This was an enterprise-level project requiring multi-team coordination to ensure success.
For this project, the Database Engineering Team partnered with a Technical Project Manager to help us engage all stakeholders to align with the goals, scope, schedule, and status of their data migration, and solicited their feedback, input, and support. Those teams have their own projects and goals in a queue, so one of our goals was to minimize how much involvement was needed from our stakeholders. By engaging them early on in the process we made sure that this project was planned for in their quarterly roadmap. We were able to whittle down the engagement needed from our application teams to a few simple steps:
- Complete the list of applications, per database, which includes the product owner, technical owner, connection properties, and other notes regarding each application in use at Collectors
- Change their documented connection strings to use a new CNAME (pointing to the new database)
- Assist with testing along with the QA team
Plan the data migration strategy and prepare the databases
The next step is planning and finalizing a strategy for migration. This depends on the data volume, maintenance windows, replication capabilities between On-prem and Cloud, and many other factors. It is important to have the right tools and skill sets needed for the migration. If possible, plan to review and clean up your databases and dependencies before migration to lighten the load as much as possible. For example, you may not want to migrate unused databases or you may not need to bring the historical data into the cloud and choose to archive it.
At Collectors, our initial approach was to bring databases on-premise to AWS in batches – but we quickly realized that cross-database relationships are so complex that it would be a much bigger project separating the databases from the instances than migrating both of them as-is.
In fact, we determined that with a little more planning and testing we could take the cloud migration one step further and consolidate 2-to-1 – thus avoiding cross-server query references and the overhead of cross-instance data replication. Fortunately, our Database Engineers Jim and Nate have complementary skillsets1 in both Database Administration and Database Development, and along with my experience we were able to push past several potential blockers. With our knowledge of the behavior of the databases, we planned to refactor stored procedures, combining databases and avoiding replications without requiring assistance from our Application Development teams.
We also finalized the migration target as AWS RDS SQL Server instead of AWS RDS Custom SQL Server, after doing POCs on both.
To simplify the actual cutover and further minimize the impact on the Application teams, we decided to use new CNAMEs for the existing 2 servers, further softening the work required of our App teams – and is a change that was able to be made well in advance of the actual migration.
Further expediency was achieved by reviewing many databases for shrinkage opportunities (removing unused tables, indexes, SQL Agent Jobs, shrinking inflated TLogs), and also decommissioning approximately a dozen databases that had negligible activity.
Choose the right data migration tools and methods
Depending on the complexity and scale of your data migration project, you may need to use different tools and methods to facilitate the process. For example, you may use data replication tools to synchronize the data between the source and target systems (like DMS) and you may also use DB native data migration tools, third-party services, or open-source tools that offer features such as data mapping, validation, testing, monitoring, and reporting. Choosing the right data migration tools and methods will help you speed up the process, reduce manual work, and ensure data reliability and security.
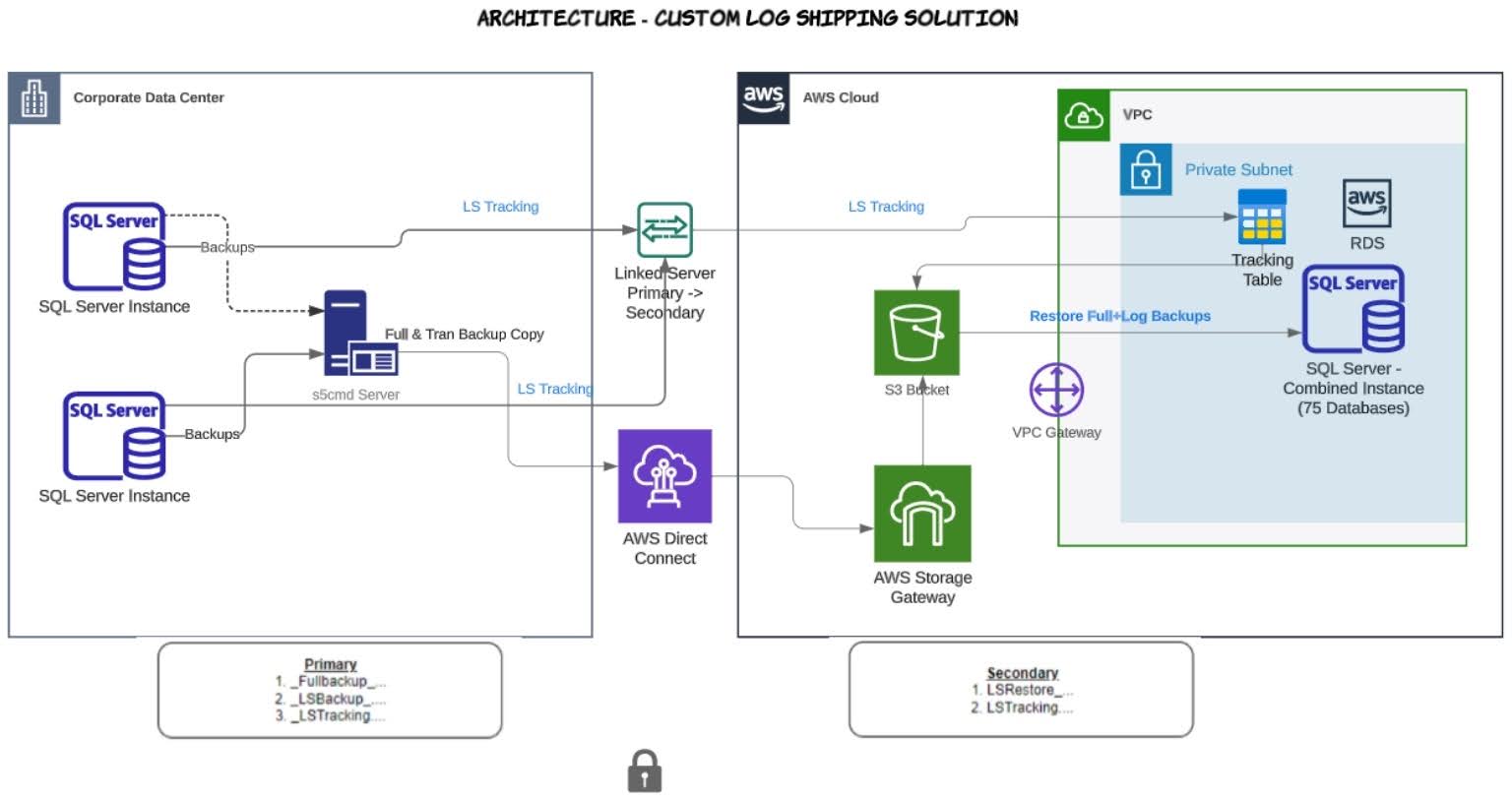
At Collectors, we partnered with the AWS RDS team to review our primary migration constraints: large data volume and a small maintenance window in which we needed to cutover, test, and (potentially) rollback. The AWS RDS team recommended a review of a previous use case created on top of a custom log shipping solution, built upon Microsoft’s tried-and-true native log shipping principles, where the transaction log backups are copied from the primary SQL Server instance to the secondary SQL Server instance and applied to each of the secondary databases individually on a scheduled basis. A tracking table records the history of backup and restore operations, and is used as the monitor. Finally, we used open-source S5CMD to efficiently and quickly copy the backups to our target S3 bucket. With this method, we could replicate all our large databases before the cutover.
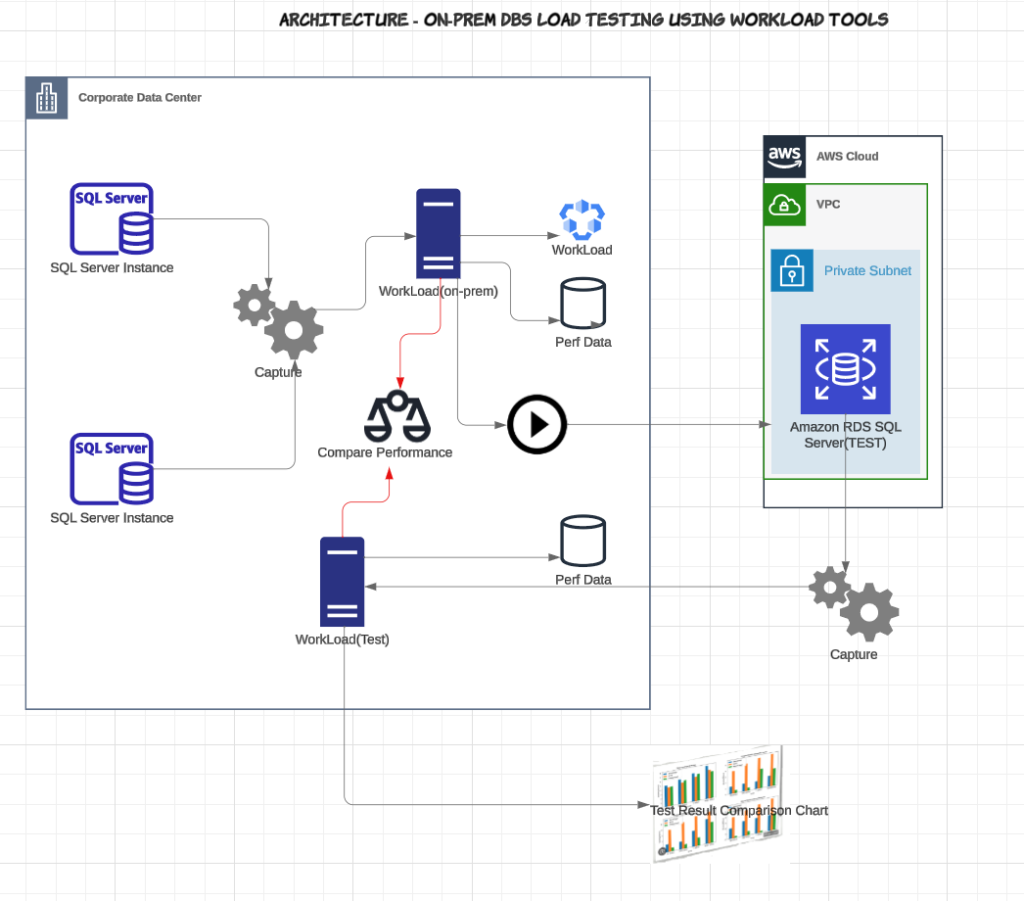
Test your workload against your target instance before going live
Before you launch your data migration, you should test it thoroughly and document metric comparisons to ensure that it works as expected and meets your quality and performance standards. You should test your data migration in a staging or testing environment that mimics the production environment as closely as possible. You should also test your data migration from different perspectives, such as data completeness, correctness, consistency, integrity, and usability. Testing your data migration before going live will help you identify and fix any errors, bugs, or issues, and ensure that your data migration is successful and smooth.
At Collectors, we used (open source) WorkloadTools (WorkloadTools | spaghettidba) – Gianluca Sartori’s command line tools to collect a workload, analyze the data, and replay the workload in real time. In fact, we were able to test the “combined” load from 2 servers against a single “consolidated” SQL Server instance. We replayed the load on different SQL Server instance sizes and classes and finalized our SQL Instance.
Prepare a living “Run Book”
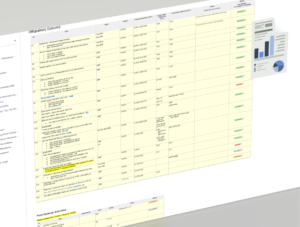
One of the most important steps before the migration is to prepare a runbook with all prerequisites, dependencies, maintenance windows, actual cutover steps, post migration validations and issues log, go/no-go decisions, and fall-back or fail-forward steps. This living document is key to success, as it becomes everyone’s go-to document for checking status of testing, issues, etc.
At Collectors, we were lucky to have this run book prepared and tested through lower environments before the production migration with details of how to perform the cutover.
The Run Book was our best friend!
Prepare for post-migration challenges
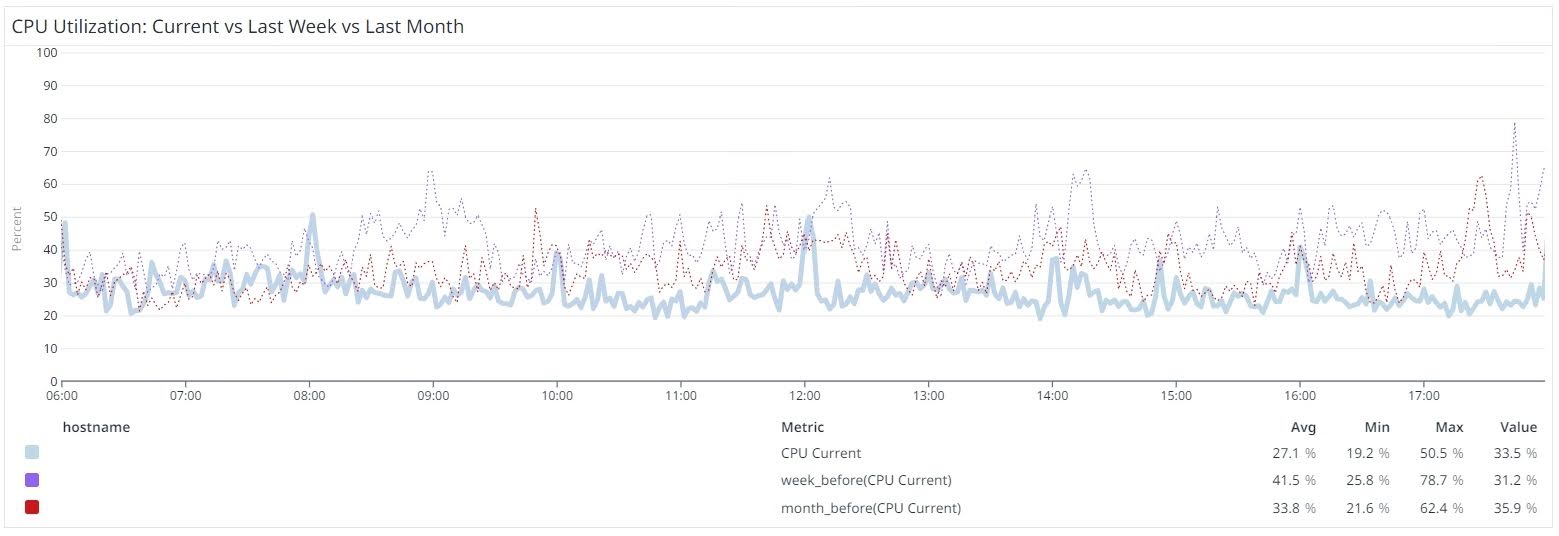
Another important (yet frequently overlooked) part of this project was to set up the right observability tools before the actual migration. This would help us in monitoring and optimizing the performance, find the root causes easily, and be appropriately alerted when adverse conditions are met. Even if we had tested the target instance sizes with load testing, there are typically challenges when the database is actually moved to a new instance because of differences in various system parameters like memory, CPU, disk IOPS, and network throughput as well as RDBMS-specific SQL Server settings like MAXDOP, CTFP, max memory, etc.
Our migration window was on a Saturday night, and systems were running well for a day and a half after migration. However, system slowness was observed and reported on Monday morning when the usual (heavy), weekday business load was introduced. CPU steadily spiked, with many departments complaining of slowness. Execution plans regressed to very poor plans, and we declared an incident and began searching for the root causes. We were able to contain the issues early and took many steps to keep the situation under control, some of which are listed below.
- Upgraded the instance class to mitigate performance issues temporarily. Thanks to being on the AWS RDS SQL Server platform, we could do that with minimal downtime.
- The best execution plans were pinned against “regressed” queries.
- Top queries consuming the most resources were tuned.
- Replicated a small set of data on new RDS to avoid the “heaviest” linked server connections back to on-prem.
- Configured the MAXDOP setting for critical databases to help query plans using parallelism.
- Set up Datadog alerts on CPU spikes, memory and other anomalies, average active sessions etc.
Conclusion
This database migration was quite challenging at times with plenty of ups and downs, but the team was able to craft an efficient migration to the cloud with no data loss, minimal downtime, resulting in the addition of all of the benefits of a hosted database provider and shifting those responsibilities from Collectors’ Database and Platform Engineering teams to AWS. As the team would find successful solutions to each piece of the migration architecture, our confidence continued to grow with each win and we knew this was going to be a successful migration. But as with any large project, with so much on the line with this migration, I cannot adequately explain the wonderful feeling of accomplishment and success as we went through our migration steps.
Ours was a successful and smooth migration thanks to the effort from my team and support from all App, QA, TPM, Product and Leadership teams. As we continue to tune and optimize (this never stops!), we are now enjoying the benefits of being in the cloud with two of our core database instances.
Thanks to my team

Jim Vogler is a senior DBE at Collectors with large scale infrastructure experience who enjoys improving, upgrading, automating, and managing complex relational database environments, especially SQL Server.
 Nate Johnson is a senior DBE at Collectors who tackles everything: query and index tuning, reporting, administration, and is our resident “data anomaly guy”. He’s been with Collectors since 2016, and has overseen several major infrastructure shifts, such as virtualization, storage consolidation, and of course, the move to cloud. He is an AWS Certified Solutions Architect.
Nate Johnson is a senior DBE at Collectors who tackles everything: query and index tuning, reporting, administration, and is our resident “data anomaly guy”. He’s been with Collectors since 2016, and has overseen several major infrastructure shifts, such as virtualization, storage consolidation, and of course, the move to cloud. He is an AWS Certified Solutions Architect.


